
GPT-Realtime-2 de OpenAI: traducción, voz y transcripción IA

OpenAI GPT-Realtime-2: La nueva era de la voz con razonamiento GPT-5
OpenAI acaba de presentar tres modelos de audio en su API que transforman la interacción por voz: razonamiento profundo, traducción simultánea y transcripción instantánea, todo en tiempo real.

OpenAI ha dado un salto definitivo hacia las interfaces de voz inteligentes con el lanzamiento de GPT-Realtime-2, el primer modelo de voz con capacidad de razonamiento de nivel GPT-5. Junto a él llegan GPT-Realtime-Translate y GPT-Realtime-Whisper, tres modelos que prometen cambiar la forma en que desarrolladores y empresas construyen aplicaciones de voz.
Estos modelos no se limitan a convertir voz en texto o viceversa. Están diseñados para escuchar, razonar, traducir y actuar mientras la conversación fluye de forma natural. Es el paso definitivo del simple «llamada y respuesta» hacia agentes de voz que realmente trabajan contigo.
GPT-Realtime-2: El cerebro con voz

GPT-Realtime-2 es el buque insignia. Es un modelo speech-to-speech (voz a voz) que integra transcripción, razonamiento, selección de herramientas y generación de voz en un solo paso. Adiós a las viejas tuberías separadas de STT + LLM + TTS. Ahora todo ocurre de forma unificada.
Entre sus capacidades más destacadas encontramos:
- Razonamiento GPT-5: Capaz de manejar solicitudes complejas, mantener el contexto y usar herramientas externas en paralelo mientras hablas.
- Esfuerzo de razonamiento configurable: Cinco niveles (minimal, low, medium, high, xhigh) que permiten equilibrar velocidad y profundidad según la tarea.
- Entrada de imágenes: Puedes mostrar una foto o captura de pantalla durante la conversación y el asistente describirá lo que ve, habilitando agentes de voz que también «miran».
- 128,000 tokens de contexto: Sesiones largas y coherentes sin perder el hilo.
- «Preambles»: La capacidad de generar relleno conversacional mientras razona, eliminando los silencios incómodos y haciendo la interacción mucho más humana.
Zillow, por ejemplo, ya está construyendo un asistente que puede buscar casas, filtrar por presupuesto y agendar visitas con una simple instrucción hablada. Priceline trabaja en viajes completos gestionados por voz, y Deutsche Telekom en experiencias de soporte multilingüe.
GPT-Realtime-Translate: El traductor universal

Si alguna vez soñaste con el Traductor Universal de Star Trek, GPT-Realtime-Translate es lo más cercano que existe. Soporta más de 70 idiomas de entrada y ofrece traducción de voz en tiempo real a 13 idiomas de salida, manteniendo el ritmo natural del hablante.
A diferencia de los traductores tradicionales que esperan a que termines de hablar, este modelo traduce sobre la marcha, incluso cuando varias personas intervienen en distintos idiomas. En las demostraciones, el sistema mantuvo la traducción fluida cuando un nuevo participante se unió hablando otro idioma.
OpenAI ofrece demos listas para probar: traducción de pestañas del navegador, llamadas telefónicas vía Twilio y videollamadas con LiveKit. Todo con una latencia casi imperceptible.
GPT-Realtime-Whisper: Transcripción instantánea

GPT-Realtime-Whisper es el modelo de transcripción streaming. Convierte voz a texto mientras la persona habla, sin esperar pausas. Ideal para subtítulos en vivo, notas de reuniones, accesibilidad y cualquier flujo de trabajo donde la inmediatez es clave.
Vimeo ya lo está utilizando para transcripción en tiempo real, y es fácil imaginar aplicaciones en educación, periodismo o atención al cliente donde cada palabra cuenta.
Precios y acceso
Estructura de precios:
- GPT-Realtime-2: $32 por millón de tokens de audio (entrada) / $64 por millón (salida). Entrada cacheada: $0.40/M.
- GPT-Realtime-Translate: $0.034 por minuto.
- GPT-Realtime-Whisper: $0.017 por minuto.
Los tres modelos están disponibles desde el 7 de mayo de 2026 a través de la Realtime API, que además sale oficialmente de beta. Los desarrolladores pueden conectarse mediante WebSocket (wss://api.openai.com/v1/realtime?model=gpt-realtime-2), WebRTC o SIP para llamadas telefónicas.
Además, se incorporan dos nuevas voces exclusivas: Cedar (masculina) y Marin (femenina), que se suman a las ocho voces existentes, todas renovadas para sonar más naturales y expresivas.
Casos de uso y el futuro de la voz
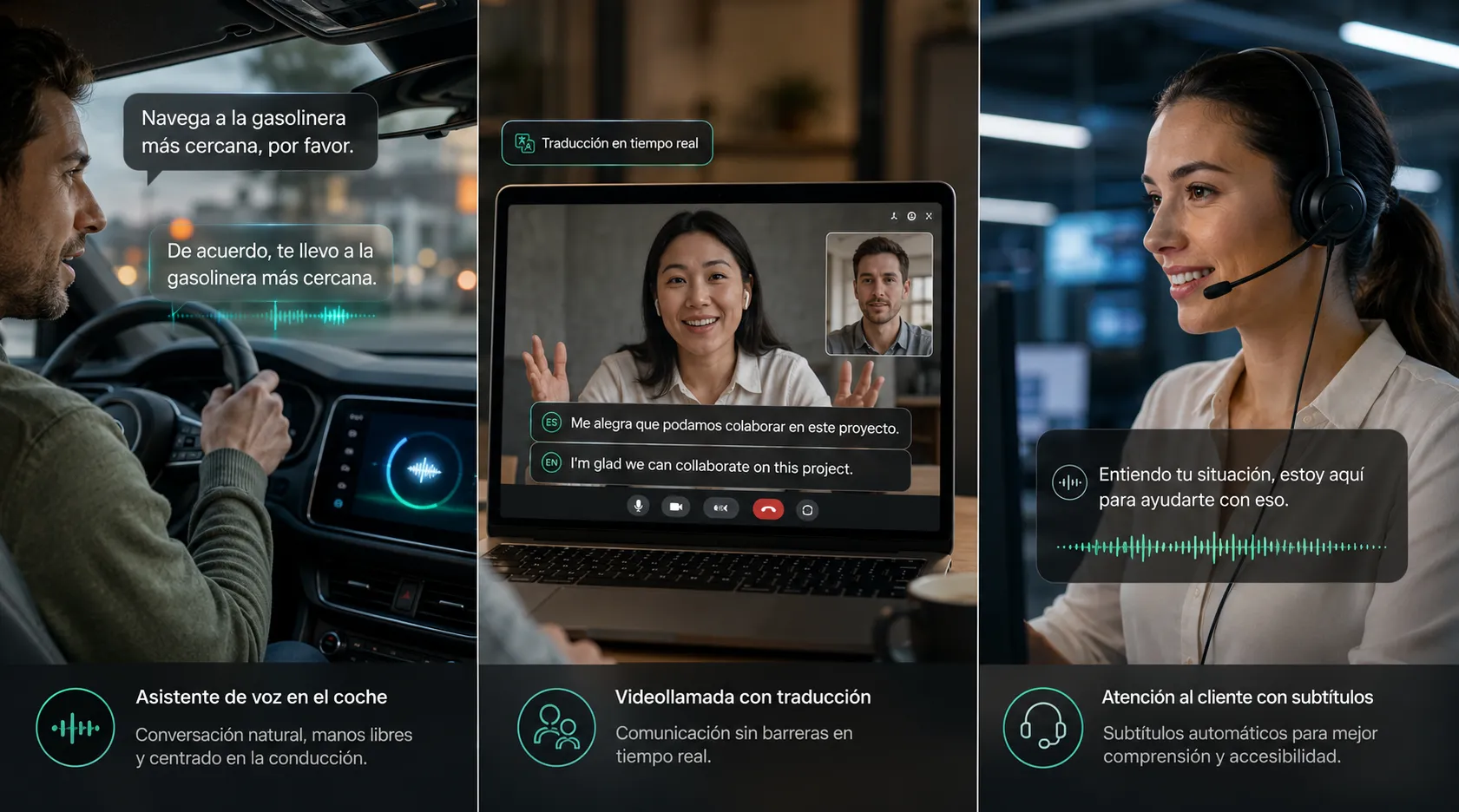
OpenAI identifica tres patrones emergentes que estos modelos hacen posibles: Voz-a-acción (describir lo que necesitas y que el sistema lo ejecute), Sistemas-a-voz (software que te habla proactivamente con información contextual) y Voz-a-voz (conversaciones que fluyen entre idiomas y tareas sin fricción).
Empresas como Zillow, Priceline, Vimeo, Deutsche Telekom y muchas más ya están integrando estos modelos. El objetivo es claro: pasar de asistentes que solo responden a agentes que escuchan, piensan, traducen, transcriben y actúan mientras la conversación sigue su curso natural.
Con 900 millones de usuarios activos semanales en ChatGPT y el Modo de Voz Avanzado como referencia, la apuesta de OpenAI por el audio es total. Incluyendo una posible familia de dispositivos de audio propios diseñados junto a Jony Ive. La voz ya no es solo un canal más: es la interfaz definitiva.
Compartir

Andrés Turcios
@NeoPunto
Mi nombre es Andrés Turcios, soy Director Ejecutivo de NeoPunto. Me especializo en desarrollo de soluciones digitales como sitios web, aplicaciones móviles, inteligencia artificial y sistemas personalizados, enfocándome en eficiencia y tecnología aplicada al crecimiento de negocios.